Автор оригинала: Nick McCullum.
Python – это отличный язык программирования для создания визуализации данных.
Однако, работая с необработанным языком программирования, такими как Python (вместо более сложных программ, как, скажем, Tableau) представляет некоторые проблемы. Разработчики, создающие визуализации, должны принять более техническую сложность в обмен на значительный вклад в то, как их визуализации выглядят.
В этом уроке я научу вас, как создавать автоматически обновлять визуализации Python. Мы будем использовать данные из IEX Cloud, и мы также будем использовать библиотеку MATPLOTLIB и некоторые простые предложения продукта Amazon Web Services.
Шаг 1: Соберите данные
Автоматически обновлять диаграммы Charts. Но прежде чем вы инвестируете время в создании их, важно понимать, нужно ли вам ваши диаграммы, которые будут автоматически обновляться.
Чтобы быть более конкретным, в ваших визуализациях нет необходимости обновлять автоматически, если данные, которые они представляют, не изменяется со временем.
Написание скрипта Python, который автоматически обновляет диаграмму годовой карьеры Майкла Джордана, будет бесполезной – его карьера окончена, и этот набор данных никогда не изменится.
Лучшие данные набора данных для автоматического обновления визуализации – это данные серии временных серий, где новые наблюдения добавляются на регулярной основе (скажем, каждый день).
В этом руководстве мы будем использовать данные фондового рынка из IEX Cloud API Отказ В частности, мы будем визуализировать исторические цены на акции для нескольких крупнейших банков в США:
- JPMorgan Chase (JPM)
- Банк Америки (BAC)
- Citigroup (C)
- Wells Fargo (WFC)
- Goldman Sachs (GS)
Первое, что вам нужно сделать, это создать учетную запись IEX Cloud и генерировать токен API.
По понятным причинам я не собираюсь публиковать свой ключ API в этой статье. Хранение собственного персонализированного ключа API в переменной под названием IEX API ключ Для вас будет достаточно, чтобы следовать.
Далее мы собираемся сохранить наш список тикеров в списке Python:
tickers = [
'JPM',
'BAC',
'C',
'WFC',
'GS',
]IEX Cloud API принимает тикеры, разделенные запятыми. Нам нужно сериализировать наш тикерный список в разделенную строку тикеров. Вот код, который мы будем использовать для этого:
#Create an empty string called `ticker_string` that we'll add tickers and commas to
ticker_string = ''
#Loop through every element of `tickers` and add them and a comma to ticker_string
for ticker in tickers:
ticker_string += ticker
ticker_string += ','
#Drop the last comma from `ticker_string`
ticker_string = ticker_string[:-1]Следующая задача, которую нам нужно для обработки, – это выбрать, какую конечную точку IEX Cloud API нам нужно пинговать.
Быстрый обзор документации IEX Cloud открывает, что у них есть Исторические цены Конечная точка, которую мы можем отправить HTTP-запрос на использование Графики ключевое слово.
Нам также нужно будет указать количество данных, которые мы запрашиваем (измеренные в течение многих лет).
Чтобы нацелиться на эту конечную точку для указанного диапазона данных, я сохранил Графики конечная точка и количество времени в отдельных переменных. Эти конечные точки затем интерполированы в сериализованный URL, который мы будем использовать для отправки нашего HTTP-запроса.
Вот код:
#Create the endpoint and years strings
endpoints = 'chart'
years = '10'
#Interpolate the endpoint strings into the HTTP_request string
HTTP_request = f'https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types={endpoints}&range={years}y&token={IEX_API_Key}'Эта интерполированная строка важна, потому что она позволяет легко изменить значение нашей строки на более позднюю дату без изменения каждого вхождения строки в нашей кодовой базе.
Теперь пришло время на самом деле сделать наш HTTP-запрос и хранить данные в структуре данных на нашем локальном компьютере.
Для этого я собираюсь использовать библиотеку Pandas для Python. В частности, данные будут храниться в Pandas DataFrame Отказ
Нам сначала нужно импортировать Пандас библиотека. По соглашению, Pandas обычно импортируется под псевдоним PD Отказ Добавьте следующий код в начало сценария для импорта PandA под нужным псевдоним:
import pandas as pd
Как только мы импортировали Pandas в наш сценарий Python, мы можем использовать его read_json Способ хранения данных из облака IEX в PandaFrame Pandas:
bank_data = pd.read_json(HTTP_request)
Печать этого датафарама внутри Jupyter ноутбук генерирует следующий вывод:
Ясно, что это не то, что мы хотим. Нам нужно будет разобрать эти данные для генерации DataFrame, которое стоит затереть.
Начать, давайте рассмотрим определенный столбец Bank_data – Скажи, bank_data ['jpm'] :
Понятно, что следующий разборный слой должен быть Диаграмма Конечная точка:
Теперь у нас есть структура данных, похожее на JSON, где каждая ячейка – дата наряду с различными точками данных о цене акций JPM на этой дате.
Мы можем обернуть эту структуру JSON-подобной JSON в PandaS DataFrame, чтобы сделать его гораздо более читаемым:
Это то, с чем мы можем работать!
Давайте напишем небольшую петлю, которая использует подобную логику, чтобы вытащить серию цен на закрытие для каждого акции в качестве Панда серии (что эквивалентно столбцу Pandas DataFrame). Мы будем хранить эти серии Panda в словаре (с ключом быть тикером) для легкого доступа позже.
for ticker in tickers:
series_dict.update( {ticker : pd.DataFrame(bank_data[ticker]['chart'])['close']} )Теперь мы можем создать наши доработанные PandaS DataFrame, имеющие дату своего индекса и столбца для закрытия цены каждого основного банка в течение последних 5 лет:
series_list = []
for ticker in tickers:
series_list.append(pd.DataFrame(bank_data[ticker]['chart'])['close'])
series_list.append(pd.DataFrame(bank_data['JPM']['chart'])['date'])
column_names = tickers.copy()
column_names.append('Date')
bank_data = pd.concat(series_list, axis=1)
bank_data.columns = column_names
bank_data.set_index('Date', inplace = True)После всего этого сделано, наше Bank_data DataFrame будет выглядеть так:
Наш сбор данных завершен. Сейчас мы готовы начать создание визуализации с помощью этого набора данных цен на акции для общедоступных банков. В качестве быстрого Recap вот сценарий, который мы построили до сих пор:
import pandas as pd
import matplotlib.pyplot as plt
IEX_API_Key = ''
tickers = [
'JPM',
'BAC',
'C',
'WFC',
'GS',
]
#Create an empty string called `ticker_string` that we'll add tickers and commas to
ticker_string = ''
#Loop through every element of `tickers` and add them and a comma to ticker_string
for ticker in tickers:
ticker_string += ticker
ticker_string += ','
#Drop the last comma from `ticker_string`
ticker_string = ticker_string[:-1]
#Create the endpoint and years strings
endpoints = 'chart'
years = '5'
#Interpolate the endpoint strings into the HTTP_request string
HTTP_request = f'https://cloud.iexapis.com/stable/stock/market/batch?symbols={ticker_string}&types={endpoints}&range={years}y&cache=true&token={IEX_API_Key}'
#Send the HTTP request to the IEX Cloud API and store the response in a pandas DataFrame
bank_data = pd.read_json(HTTP_request)
#Create an empty list that we will append pandas Series of stock price data into
series_list = []
#Loop through each of our tickers and parse a pandas Series of their closing prices over the last 5 years
for ticker in tickers:
series_list.append(pd.DataFrame(bank_data[ticker]['chart'])['close'])
#Add in a column of dates
series_list.append(pd.DataFrame(bank_data['JPM']['chart'])['date'])
#Copy the 'tickers' list from earlier in the script, and add a new element called 'Date'.
#These elements will be the column names of our pandas DataFrame later on.
column_names = tickers.copy()
column_names.append('Date')
#Concatenate the pandas Series together into a single DataFrame
bank_data = pd.concat(series_list, axis=1)
#Name the columns of the DataFrame and set the 'Date' column as the index
bank_data.columns = column_names
bank_data.set_index('Date', inplace = True)Шаг 2: Создайте график, которую вы хотите обновить
В этом руководстве мы будем работать с библиотекой визуализации MatPlotlib для Python.
Matplotlib – это чрезвычайно сложная библиотека, и люди проводят годы, овладевающие его их полной степенью. Соответственно, пожалуйста, имейте в виду, что мы только царапаем поверхность возможностей Matlolotlib в этом руководстве.
Мы начнем, импортируя библиотеку MatPlotlib.
Как импортировать matplotlib
По соглашению, данные ученые в целом импортируют Pyplot Библиотека MATPLOTLIB под псевдоним PLT Отказ
Вот полное утверждение импорта:
import matplotlib.pyplot as plt
Вам нужно будет включить это в начале любого файла Python, который использует MATPLOTLIB для создания визуализации данных.
Существуют также другие аргументы, которые вы можете добавить с помощью библиотеки MATPLOTLIB Import, чтобы ваши визуализации были легче работать с.
Если вы работаете через этот учебник в ноутбуке Jupyter, вы можете включить следующее утверждение, которое приведет к появлению ваших визуализаций, не требуя, чтобы написать PLT.Show () утверждение:
%matplotlib inline
Если вы работаете в ноутбуке Jupyter на MacBook с дисплеем сетчатки, вы можете использовать следующие утверждения, чтобы улучшить разрешение вашего визуализации MATPLOTLIB в ноутбуке:
from IPython.display import set_matplotlib_formats
set_matplotlib_formats('retina')С той с пути, давайте начнем создавать наши первые визуализации данных, используя Python и Matplotlib!
Форматирование форматирования MATPLOTLIB
В этом уроке вы узнаете, как создавать бакплаты, разбросы и гистограммы в Python с помощью MATPLOTLIB. Я хочу пройти несколько оснований форматирования в Matplotlib, прежде чем мы начнем создавать реальные визуализации данных.
Во-первых, почти все, что вы делаете в Matplotlib, будут включать в себя методы вызовов на PLT Объект, который является псевдоним, который мы импортировали MatPlotlib как.
Во-вторых, вы можете добавить названия на визуализации MATPLOTLIB, позвонив PLT.TITLE () и прохождение в желаемом названии в виде строки.
В-третьих, вы можете добавить этикетки на ваши оси X и Y, используя plt.xlabel () и plt.ylabel () методы.
Наконец, с тремя методами, которые мы просто обсуждали – PLT.TITLE () , plt.xlabel () и plt.ylabel () – Вы можете изменить размер шрифта заголовка с fontsize аргумент
Давайте копаем, чтобы создать нашу первую визуализацию MATPLOTLIB всерьез.
Как создавать коробки в Matplotlib
Boxplots являются одним из самых фундаментальных визуализации данных, доступных для ученых данных.
MATPLOTLIB позволяет нам создавать бакплаты с boxplot функция.
Поскольку мы будем создавать Boxplots вдоль наших столбцов (а не вдоль наших строк), мы также захочем транспонировать наш DataFrame внутри boxplot Способ вызова.
plt.boxplot(bank_data.transpose())
Это хорошее начало, но нам нужно добавить некоторую стайлинг, чтобы сделать эту визуализацию легко интерпретировать для внешнего пользователя.
Во-первых, давайте добавим название диаграммы:
plt.title('Boxplot of Bank Stock Prices (5Y Lookback)', fontsize = 20)Кроме того, полезно пометить оси X и Y, как упомянуто ранее:
plt.xlabel('Bank', fontsize = 20)
plt.ylabel('Stock Prices', fontsize = 20)Нам также потребуется добавить метки для определенных столбцов на ось x, чтобы это было понятно, какой BoxPlot принадлежит каждому банку.
Следующий код делает трюк:
ticks = range(1, len(bank_data.columns)+1) labels = list(bank_data.columns) plt.xticks(ticks,labels, fontsize = 20)
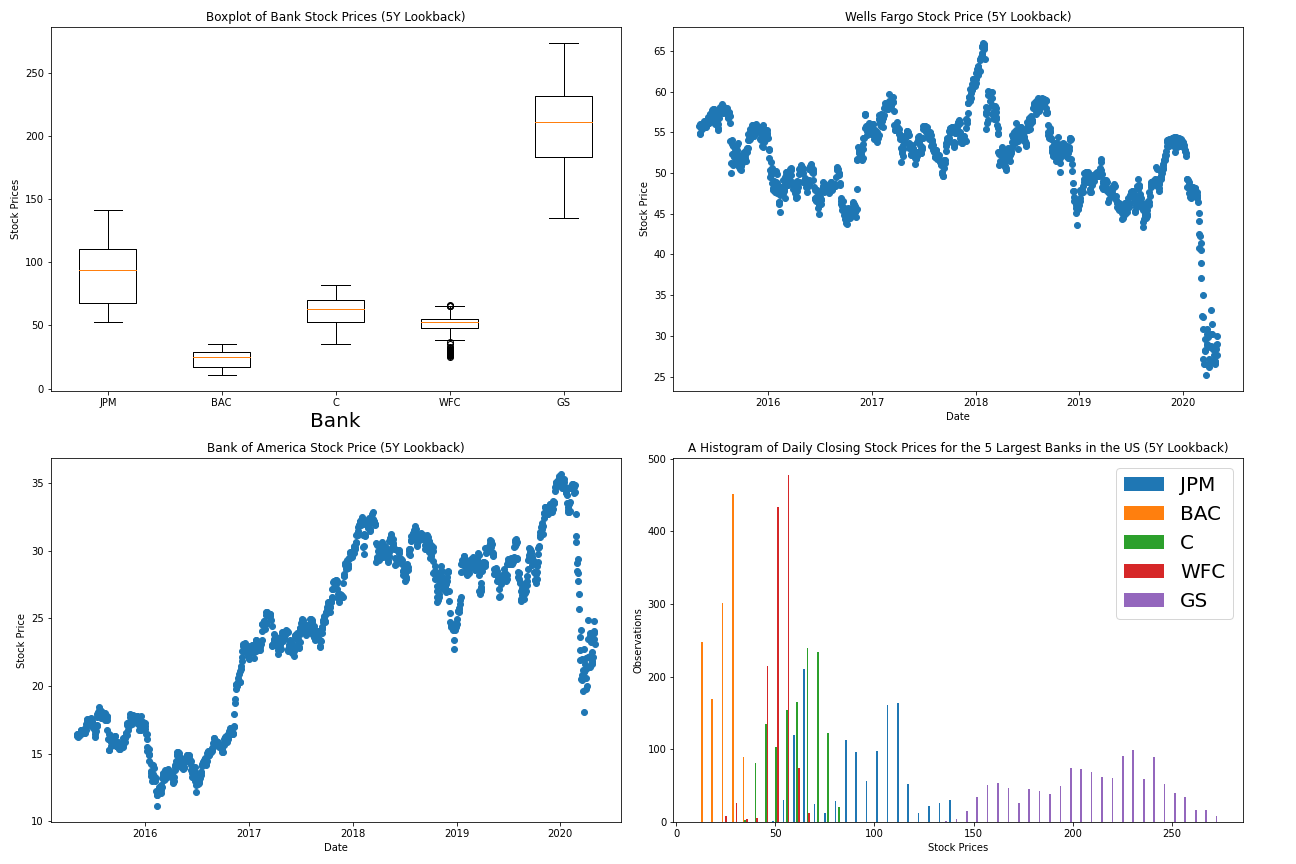
Также так, у нас есть BoxPlot, который представляет некоторые полезные визуализации в Matplotlib! Понятно, что Goldman Sachs торговал по самой высокой цене за последние 5 лет, а запас Банка Америки торгуется самым низким. Также интересно отметить, что у Wells Fargo есть самые выгодные баллы данных.
В качестве RECAP вот полный код, который мы использовали для создания наших ящиков:
########################
#Create a Python boxplot
########################
#Set the size of the matplotlib canvas
plt.figure(figsize = (18,12))
#Generate the boxplot
plt.boxplot(bank_data.transpose())
#Add titles to the chart and axes
plt.title('Boxplot of Bank Stock Prices (5Y Lookback)', fontsize = 20)
plt.xlabel('Bank', fontsize = 20)
plt.ylabel('Stock Prices', fontsize = 20)
#Add labels to each individual boxplot on the canvas
ticks = range(1, len(bank_data.columns)+1)
labels = list(bank_data.columns)
plt.xticks(ticks,labels, fontsize = 20)Как создавать разбросы в matplotlib
Рассеяния Может быть создан в Matplotlib, используя plt.scatter метод.
разброс Метод имеет два необходимых аргумента – A х Значение и A y значение.
Давайте сюжетам цену акций Wells Fargo с течением времени, используя PLT.SCatter () метод.
Первое, что нам нужно сделать, это создать нашу переменную оси X, называемую даты :
dates = bank_data.index.to_series()
Далее мы будем изолировать цены запасов Wells Fargo в отдельной переменной:
WFC_stock_prices = bank_data['WFC']
Теперь мы можем построить визуализацию, используя plt.scatter Метод:
plt.scatter(dates, WFC_stock_prices)
Подождите минутку – эти этикетки этого графика невозможно прочитать!
В чем проблема?
Ну, MATPLOTLIB в настоящее время не признает, что ось X содержит даты, поэтому оно не проводится должным образом на этикетках.
Чтобы исправить это, нам нужно преобразовать каждый элемент даты Серия в datetime тип данных. Следующая команда – самый читаемый способ сделать это:
dates = bank_data.index.to_series() dates = [pd.to_datetime(d) for d in dates]
После запуска plt.scatter Снова способ, вы будете генерировать следующую визуализацию:
Намного лучше!
Наш последний шаг – добавить названия на график и ось. Мы можем сделать это со следующими утверждениями:
plt.title("Wells Fargo Stock Price (5Y Lookback)", fontsize=20)
plt.ylabel("Stock Price", fontsize=20)
plt.xlabel("Date", fontsize=20)Как RECAP, вот код, который мы использовали для создания этого ScatterPlot:
########################
#Create a Python scatterplot
########################
#Set the size of the matplotlib canvas
plt.figure(figsize = (18,12))
#Create the x-axis data
dates = bank_data.index.to_series()
dates = [pd.to_datetime(d) for d in dates]
#Create the y-axis data
WFC_stock_prices = bank_data['WFC']
#Generate the scatterplot
plt.scatter(dates, WFC_stock_prices)
#Add titles to the chart and axes
plt.title("Wells Fargo Stock Price (5Y Lookback)", fontsize=20)
plt.ylabel("Stock Price", fontsize=20)
plt.xlabel("Date", fontsize=20)Как создавать гистограммы в matplotlib
Гистограммы Визуализации данных позволяют увидеть распределение наблюдений в наборе данных.
Гистограммы могут быть созданы в MatPlotlib, используя PLT.Hist метод.
Давайте создадим гистограмму, которая позволяет нам увидеть распределение различных цен на акции в наших Bank_data DataSet (обратите внимание, что нам нужно будет использовать транспонировать Метод внутри PLT.Hist Так же, как мы сделали с PLT.BoxPlot ранее):
plt.hist(bank_data.transpose())
Это интересная визуализация, но у нас все еще есть много.
Первое, что вы, вероятно, заметили, что разные колонны гистограммы имеют разные цвета. Это намеренно. Цвета разделяют различные колонны в наших панды DataFrame.
С этим сказанным, эти цвета бессмыслены без легенды. Мы можем добавить легенду на нашу гистограмму MatPlotlib со следующим утверждением:
plt.legend(bank_data.columns,fontsize=20)
Вы также можете изменить Bin Count Гистограммы, которые изменяются, сколько ломтиков набор данных делится на при том, чтобы создать наблюдения в столбцы гистограммы.
В качестве примера, вот как изменить количество BINS на гистограмме до 50 :
plt.hist(bank_data.transpose(), bins = 50)
Наконец, мы добавим заголовки на гистограмму и его оси, используя те же операторы, которые мы использовали в наших других визуализациях:
plt.title("A Histogram of Daily Closing Stock Prices for the 5 Largest Banks in the US (5Y Lookback)", fontsize = 20)
plt.ylabel("Observations", fontsize = 20)
plt.xlabel("Stock Prices", fontsize = 20)В качестве RECAP вот полный код, необходимый для создания этой гистограммы:
########################
#Create a Python histogram
########################
#Set the size of the matplotlib canvas
plt.figure(figsize = (18,12))
#Generate the histogram
plt.hist(bank_data.transpose(), bins = 50)
#Add a legend to the histogram
plt.legend(bank_data.columns,fontsize=20)
#Add titles to the chart and axes
plt.title("A Histogram of Daily Closing Stock Prices for the 5 Largest Banks in the US (5Y Lookback)", fontsize = 20)
plt.ylabel("Observations", fontsize = 20)
plt.xlabel("Stock Prices", fontsize = 20)Как создавать подломы в Matplotlib
В Matplotlib, подломы Являются ли имя, которое мы используем для обозначения нескольких участков, которые создаются на одном хоменте, используя один скрипт Python.
Подмороты могут быть созданы с помощью plt.subplot команда. Команда занимает три аргумента:
- Количество строк в сетке Subplot
- Количество столбцов в Subplot Grid
- Какой Subplot вы в настоящее время выбрали
Давайте создадим 2×2 Subplot Grid, которая содержит следующие диаграммы (в этом конкретном порядке):
- BoxPlot, который мы создали ранее
- ScatterPlot, который мы создали ранее
- Подобный ScattePlot, который использует
BACданные вместоWFCданные - Гистограмма, которую мы создали ранее
Во-первых, давайте создадим Subplot Grid:
plt.subplot(2,2,1) plt.subplot(2,2,2) plt.subplot(2,2,3) plt.subplot(2,2,4)
Теперь, когда у нас есть пустой холст Subplot, нам просто нужно скопировать/вставить код, который нам нужен для каждого сюжета после каждого вызова plt.subplot метод.
В конце блока кода мы добавляем plt.tight_layout Метод, который исправляет множество распространенных проблем форматирования, возникающих при генерации подломов MATPLOTLIB.
Вот полный код:
################################################
################################################
#Create subplots in Python
################################################
################################################
########################
#Subplot 1
########################
plt.subplot(2,2,1)
#Generate the boxplot
plt.boxplot(bank_data.transpose())
#Add titles to the chart and axes
plt.title('Boxplot of Bank Stock Prices (5Y Lookback)')
plt.xlabel('Bank', fontsize = 20)
plt.ylabel('Stock Prices')
#Add labels to each individual boxplot on the canvas
ticks = range(1, len(bank_data.columns)+1)
labels = list(bank_data.columns)
plt.xticks(ticks,labels)
########################
#Subplot 2
########################
plt.subplot(2,2,2)
#Create the x-axis data
dates = bank_data.index.to_series()
dates = [pd.to_datetime(d) for d in dates]
#Create the y-axis data
WFC_stock_prices = bank_data['WFC']
#Generate the scatterplot
plt.scatter(dates, WFC_stock_prices)
#Add titles to the chart and axes
plt.title("Wells Fargo Stock Price (5Y Lookback)")
plt.ylabel("Stock Price")
plt.xlabel("Date")
########################
#Subplot 3
########################
plt.subplot(2,2,3)
#Create the x-axis data
dates = bank_data.index.to_series()
dates = [pd.to_datetime(d) for d in dates]
#Create the y-axis data
BAC_stock_prices = bank_data['BAC']
#Generate the scatterplot
plt.scatter(dates, BAC_stock_prices)
#Add titles to the chart and axes
plt.title("Bank of America Stock Price (5Y Lookback)")
plt.ylabel("Stock Price")
plt.xlabel("Date")
########################
#Subplot 4
########################
plt.subplot(2,2,4)
#Generate the histogram
plt.hist(bank_data.transpose(), bins = 50)
#Add a legend to the histogram
plt.legend(bank_data.columns,fontsize=20)
#Add titles to the chart and axes
plt.title("A Histogram of Daily Closing Stock Prices for the 5 Largest Banks in the US (5Y Lookback)")
plt.ylabel("Observations")
plt.xlabel("Stock Prices")
plt.tight_layout()Как видите, с некоторыми основными знаниями относительно легко создавать красивые визуализации данных с использованием MATPLOTLIB.
Последнее, что нам нужно сделать, это сохранить визуализацию как .png Файл в нашем текущем рабочем каталоге. Matplotlib имеет отличную встроенную функциональность для этого. Просто добавьте оператор следуйте сразу после завершения четвертого субплата:
################################################
#Save the figure to our local machine
################################################
plt.savefig('bank_data.png')В оставшейся части этого учебника вы узнаете, как запланировать эту матрицу Subplot автоматически обновлять на вашем Live веб-сайте каждый день.
Шаг 3: Создайте учетную запись Amazon Web Services
Пока в этом руководстве мы узнали, как:
- Источник данных фондового рынка, которые мы собираемся визуализировать с IEX Cloud API
- Создайте замечательные визуализации, используя эти данные с библиотекой MATPLOTLIB для Python
В оставшейся части этого учебника вы узнаете, как автоматизировать эти визуализации, что они обновляются по конкретному графику.
Для этого мы будем использовать возможности облачных вычислений Amazon Web Services. Вам нужно сначала создать учетную запись AWS.
Перейдите к этот URL и нажмите кнопку «Создать учетную запись AWS» в правом верхнем углу:
Веб-приложение AWS проведет вас через шаги для создания учетной записи.
Как только ваша учетная запись была создана, мы можем начать работать с двумя услугами AWS, которые нам понадобится для наших визуализаций: AWS S3 и AWS EC2.
Шаг 4: Создайте ведро AWS S3 для хранения ваших визуализаций
AWS S3 Стенды для простого хранения. Это одно из самых популярных предложений облачных вычислений, доступных в веб-сервисах Amazon. Разработчики используют AWS S3 для хранения файлов и доступа к ним позже через URL-адреса для общественности.
Чтобы сохранить эти файлы, мы должны сначала создать то, что называется AWS S3 Ведро , что является модным словом для папки, которая хранит файлы в AWS. Для этого сначала перейдите к панели Dashboard S3 в веб-сервисах Amazon.
На правой стороне приборной панели Amazon S3 нажмите Создать ведро , как показано ниже:
На следующем экране AWS попросит вас выбрать имя для вашего нового ковша S3. Для целей этого учебника мы будем использовать имя ведра Ник-первое ведро Отказ
Далее вам нужно будет прокрутить вниз и установить ваши разрешения для ведра. Поскольку файлы, которые мы будем загружать, предназначены для публично доступны (в конце концов, мы будем встраивать их на страницах на веб-сайте), то вы захотите сделать разрешения как можно более открытыми.
Вот конкретный пример того, как следует выглядеть ваши разрешения AWS S3:
Эти разрешения очень LAX, и для многих случаев использования не являются приемлемыми (хотя они действительно соответствуют требованиям этого урока). Из-за этого AWS потребует от вас подтвердить следующее предупреждение перед созданием вашего ведра AWS S3:
Как только все это сделано, вы можете прокрутить до нижней части страницы и нажмите Создать ведро Отказ Теперь вы готовы продолжить!
Шаг 5: Измените скрипт Python, чтобы сохранить ваши визуализации на AWS S3
Наш сценарий Python в своей текущей форме предназначен для создания визуализации, а затем сохранить эту визуализацию на наш локальный компьютер. Теперь нам нужно изменить наш сценарий, чтобы вместо этого сохранить .png Файл к ведрю AWS S3, который мы только что создали (который, как напоминание называется Nicks-First-Bucket ).
Инструмент, который мы будем использовать для загрузки нашего файла на наше ведро AWS S3, называется Boto3 Комплект разработки программного обеспечения Amazon Web Services (SDK) для Python.
Во-первых, вам нужно установить Boto3 на твоей машине. Самый простой способ сделать это использует Пип Пакет менеджер:
pip3 install boto3
Далее нам нужно импортировать Boto3 в наш сценарий Python. Мы делаем это, добавив следующее утверждение вблизи начала нашего сценария:
import boto3
Учитывая глубину и широту товаров Amazon Web Services, Boto3 Является безумной сложной библиотекой Python.
К счастью, нам нужно только использовать некоторые из самых основных функциональных возможностей Boto3 Отказ
Следующий код кода будет загружать нашу окончательную визуализацию на Amazon S3.
################################################
#Push the file to the AWS S3 bucket
################################################
s3 = boto3.resource('s3')
s3.meta.client.upload_file('bank_data.png', 'nicks-first-bucket', 'bank_data.png', ExtraArgs={'ACL':'public-read'})Как вы можете видеть, upload_file метод Boto3 берет несколько аргументов. Давайте сломаемся, один-за один:
bank_data.pngэто название файла на нашем локальном компьютере.Ник-первое ведроэто имя ведра S3, которое мы хотим загрузить.bank_data.pngЭто имя, которое мы хотим, чтобы файл имел после того, как он загружен в ведро AWS S3. В этом случае он такой же, как первый аргумент, но это не должно быть.Experargs = {'acl': «Государственный читал»}Значит, файл должен быть читабелен публикой после того, как он нажал к ведру AWS S3.
Запуск этого кода теперь приведет к ошибке. В частности, Python выброс следующий исключение:
S3UploadFailedError: Failed to upload bank_data.png to nicks-first-bucket/bank_data.png: An error occurred (NoSuchBucket) when calling the PutObject operation: The specified bucket does not exist
Почему это?
Ну, это потому, что мы еще не настроили наш локальный компьютер, чтобы взаимодействовать с веб-сервисами Amazon через Boto3 Отказ
Для этого мы должны запустить AWS Configure Команда из нашей командной строки интерфейса и добавьте наши клавиши доступа. Эта часть документации от Amazon разделяет больше информации о том, как настроить интерфейс командной строки AWS.
Если вы предпочитаете не перемещаться по FreeCodeCamp.org, вот быстрые шаги для настройки вашего AWS CLI.
Во-первых, Наведите имя пользователя в правом верхнем углу, как это:
Нажмите Мои учетные данные о безопасности Отказ
На следующем экране вы хотите нажать Ключи доступа (ID ключа доступа и ключа секретного доступа Выпадайте, затем нажмите Создать новый ключ доступа .
Это подскажет вам скачать .csv Файл, который содержит как ваша клавиша доступа, так и ваш ключ секретного доступа. Сохраните их в безопасном месте.
Затем запустите интерфейс командной строки Amazon Web Services, набрав AWS Configure в вашей командной строке. Это предложит вам ввести ключ доступа и секретный ключ доступа.
Как только это сделано, ваш скрипт должен функционировать как предназначено. Запустите скрипт и проверьте, чтобы убедиться, что ваша визуализация Python была должным образом загружена на AWS S3, глядя внутрь ведро, которое мы создали ранее:
Визуализация была успешно загружена. Теперь мы готовы встроить визуализацию на нашем сайте!
Шаг 6: встроить визуализацию на вашем сайте
Как только визуализация данных была загружена в AWS S3, вы захотите встроить визуализацию где-то на вашем сайте. Это может быть в блоге или любой другой странице на вашем сайте.
Для этого нам нужно будет захватить URL-адрес изображения из нашего ведра S3. Щелкните имя изображения в ведре S3, чтобы навигаться к странице, определенной файлом для этого элемента. Это будет выглядеть так:
Если вы прокрутите до нижней части страницы, будет под названием поле Объект URL Это выглядит так:
https://nicks-first-bucket.s3.us-east-2.amazonaws.com/bank_data.png
Если вы копируете и вставьте этот URL в веб-браузер, он фактически загружает bank_data.png Файл, который мы загрузили ранее!
Чтобы встроить это изображение на веб-страницу, вы захотите передать его в HTML IMG Тег как SRC атрибут. Вот как мы бы встроили наши bank_data.png Изображение на веб-страницу с помощью HTML:
Примечание : В реальном изображении встроен на веб-сайт, было бы важно включить Alt Теги для целей доступности.
В следующем разделе мы узнаем, как планировать наш сценарий Python для периодически бегать так, чтобы данные в bank_data.png всегда актуальна.
Шаг 7: Создайте экземпляр AWS EC2
Мы будем использовать AWS EC2, чтобы назначить наш сценарий Python для периодической работы.
AWS EC2 Стенды для упругого вычислительного облака и, наряду с S3, является одним из самых популярных облачных услуг облачных вычислений Amazon.
Он позволяет арендовать небольшие блоки вычислительной мощности (называемые экземплярами) на компьютерах в центрах данных Amazon и расплачивают эти компьютеры для выполнения заданий для вас.
AWS EC2 – довольно замечательный сервис, потому что если вы арендуете некоторые из своих небольших компьютеров, то вы фактически вы квалифицируете для свободного уровня AWS. По словам по-разному, прилежное использование ценообразования в пределах AWS EC2 позволит вам избежать оплаты любых денег.
Для начала нам нужно будет создать наш первый экземпляр EC2. Для этого перейдите на панель инструментов EC2 в консоли управления AWS и нажмите Экземпляр запуски :
Это приведет вас на экран, который содержит все доступные типы экземпляров в AWS EC2. Здесь почти невероятное количество вариантов. Мы хотим, что тип экземпляра, который квалифицируется как Свободный уровень, имеющий право на – В частности, я выбрал Amazon Linux 2 AMI (HVM), тип объема SSD :
Нажмите Выберите продолжать.
На следующей странице AWS попросит вас выбрать спецификации для вашей машины. Поля, которые вы можете выбрать, включают в себя:
СемьяТипVCPUS.объем памятиХранение экземпляра (ГБ)EBS-оптимизированПроизводительность сетиПоддержка IPv6
Для целей этого учебника мы просто хотим выбрать одну машину, имеющую право на свободный уровень. Он характеризуется маленькой зеленой этикеткой, которая выглядит так:
Нажмите Отзыв и запустить внизу экрана, чтобы продолжить.
Следующий экран представит детали вашего нового экземпляра для просмотра.
Быстро просмотрите спецификации машины, затем нажмите Запуск в правом нижнем углу.
Нажав на Запуск Кнопка будет вызвать всплывающее окно, которое просит вас Выберите существующую ключевую пару или создайте новую ключевую пару Отказ
Пара ключей состоит из открытого ключа, который удерживает AWS и закрытый ключ, который вы должны загрузить и хранить в A .pem файл.
Вы должны иметь доступ к этому .pem файл для доступа к экземпляру EC2 (как правило, через SSH). У вас также есть возможность продолжить без ключевой пары, но это не рекомендуется по соображениям безопасности.
Как только это сделано, ваш экземпляр запустится! Поздравляем с запуском вашего первого показателя на одном из самых важных инфраструктурных услуг Amazon Web Services.
Далее вам нужно будет нажать свой скрипт Python в свой экземпляр EC2.
Вот универсальное утверждение состояния команды, которое позволяет вам переместить файл в экземпляр EC2:
scp -i path/to/.pem_file path/to/file username@host_address.amazonaws.com:/path_to_copy
Запустите это утверждение с необходимыми заменами для перемещения bank_stock_data.py в экземпляр EC2.
Возможно, вы можете поверьте, что теперь вы можете запустить ваш сценарий Python из своего экземпляра EC2. К сожалению, это не случай. Ваш экземпляр EC2 не поставляется с необходимыми пакетами Python.
Чтобы установить использованные пакеты, которые мы использовали, вы можете либо экспортировать A требования .txt Файл и импортировать правильные пакеты, используя Пип или вы можете просто запустить следующее:
sudo yum install python3-pip pip3 install pandas pip3 install boto3
Сейчас мы готовы запланировать наш сценарий Python для проведения периодической основы на нашем экземпляре EC2! Мы исследуем это в следующем разделе нашей статьи.
Шаг 8: Расписание сценариев Python периодически запускается на AWS EC2
Единственный шаг, который остается в этом руководстве, состоит в том, чтобы запланировать наши bank_stock_data.py Файл для периодической работы в нашем экземпляре EC2.
Мы можем использовать утилиту командной строки, называемой Cron сделать это.
Cron Работает, требуя того, чтобы вы указать две вещи:
- Как часто вы хотите выполнить задачу (называемая работой
CRON), выраженная с помощью выражения CRON - Что нужно выполнить, когда задание CRON запланировано
Во-первых, давайте начнем с создания выражения CRON.
Cron Выражения могут показаться гиббервами в аутсайдере. Например, вот Cron Выражение, которое означает «каждый день в полдень»:
00 12 * * *
Я лично использую Crontab Guru Веб-сайт, который является отличным ресурсом, который позволяет вам видеть (в Условиях Лэймана), что ваш Cron выражение означает.
Вот как вы можете использовать веб-сайт Crontab Guru, чтобы запланировать работу CRON, чтобы запустить каждое воскресенье в 7 утра:
Теперь у нас есть инструмент (Crontab Guru), который мы можем использовать для создания наших Cron выражение. Теперь нам нужно проинструктировать Cron Демон нашего экземпляра EC2, чтобы запустить наши bank_stock_data.py Файл каждое воскресенье в 7 утра.
Для этого мы сначала создам новый файл в вашем экземпляре EC2 под названием Банк акции _data.cron Отказ Так как я использую Vim Текстовый редактор, команда, которую я использую для этого:
vim bank_stock_data.cron
В рамках этого .cron Файл, должна быть одна строка, которая выглядит так: (Cron Expression) (оператор для выполнения) Отказ Наше Cron выражение – 00 7 * * 7 И наше заявление для выполнения – python3 bank_stock_data.py Отказ
Положить все это вместе, и вот что окончательное содержание bank_stock_data.cron должно быть:
00 7 * * 7 python3 bank_stock_data.py
Последний шаг этого учебника – импортировать bank_stock_data.cron файл в Crontab нашего экземпляра EC2. Crontab По сути, файл, который объединяет рабочие места для Cron демон, чтобы периодически выступать.
Давайте сначала наступим момент, чтобы расследовать, что в нашем Crontab Отказ Следующая команда печатает содержимое Crontab в нашу консоль:
crontab -l
Поскольку мы ничего не добавили в наше crontab, и мы создали только наш экземпляр EC2 несколько минут назад, то это утверждение не должно печатать ничего.
Теперь давайте импомнем bank_stock_data.cron в Crontab Отказ Вот утверждение для этого:
crontab bank_stock_data.cron
Теперь мы должны быть в состоянии распечатать содержимое нашего Crontab и увидеть содержимое bank_stock_data.cron Отказ
Чтобы проверить это, запустите следующую команду:
crontab -l
Это должно печатать:
00 7 * * 7 python3 bank_stock_data.py
Последние мысли
В этом руководстве вы узнали, как создавать красивые визуализации данных, используя Python и Matplotlib, который периодически обновляет. В частности, мы обсуждали:
- Как скачать и анализировать данные из облака IEX, один из моих любимых источников данных для качественных финансовых данных
- Как отформатировать данные в рамках PandaS DataFrame
- Как создать визуализации данных в Python с помощью MATPLOTLIB
- Как создать учетную запись с Amazon Web Services
- Как загружать статические файлы на AWS S3
- Как встроить
.pngФайлы, размещенные на AWS S3 на страницах на сайте - Как создать экземпляр AWS EC2
- Как запланировать сценарий Python для периодической работы AWS EC2, используя
кринов
Эта статья была опубликована Ником МакКалумом, Кто Обучает людям, как кодировать на своем сайте Отказ